Case study · 2025 to 2026
TrueMem: a model-agnostic memory layer for AI applications
A persistent, two-tier (short-term + long-term) memory service for LLM applications. Distilled facts replace verbatim history, semantic retrieval surfaces what matters, and the same memory follows users across any model.
Senior Engineer · Architecture, design, build, ship
Stack
Python · FastAPI · Postgres · pgvector · Redis (queues) · OpenAI / Anthropic / TrueFoundry AI Gateway
Outcomes
- ~10 ms similarity search and ~45 ms end-to-end context preparation, dominated by embedding latency and parallelized against DB fetches.
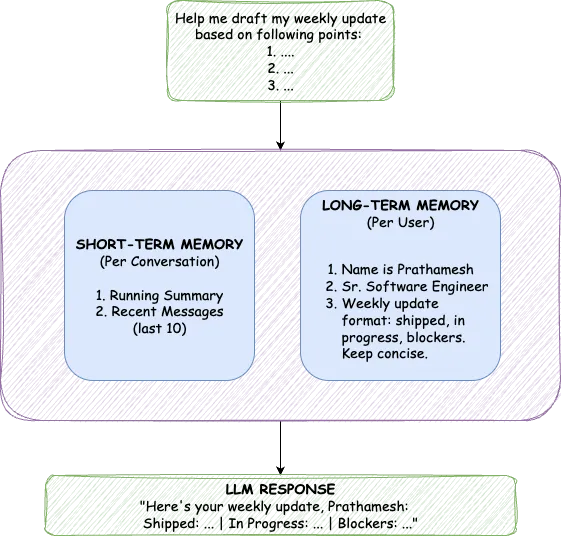
- Two-tier memory architecture (STM: running summary + last 20 messages; LTM: vector-stored, importance-scored, semantically deduplicated facts) modelled after working vs. long-term human memory.
- Model-agnostic by design: memory lives outside the model, so consumers can swap GPT, Claude, or a fine-tuned in-house model without losing user context.
What I owned
The full design and build of TrueMem: the dual-tier memory model, the explicit-vs-automatic memory extraction pipeline, semantic deduplication (≥85% similarity collapses to an update, not a duplicate), importance-scoring (1 to 5) with lifecycle-managed pruning, async summary compression, and the public byline on the TrueFoundry engineering blog.
What shipped
A production memory service that any LLM application calls in two HTTP hops: fetch context before the model, log the interaction after. Short-term memory keeps recent turns coherent without blowing the context window; long-term memory stores distilled, deduped facts about each user, scoped per-user, retrievable by cosine similarity in under 10 ms. Heavy work (summarization, extraction) runs asynchronously on Redis-backed workers so the synchronous read path stays under 80 ms total.
Lessons
RAG and “bigger context windows” are answering the wrong question for user memory. RAG retrieves documents; memory needs to retrieve relationships. Context windows pay tokens for amnesia with extra steps. A small dedicated layer (pgvector, two importance-aware tables, parallelized fetch) gets you AI that actually remembers, and it gets you vendor-portability for free. The interesting work is in the data shape (what counts as a fact, how facts age, how duplicates collapse), not the model.