Case study · 2024 to present
From IVR to agentic: multi-vector retrieval for pharmacy intent classification
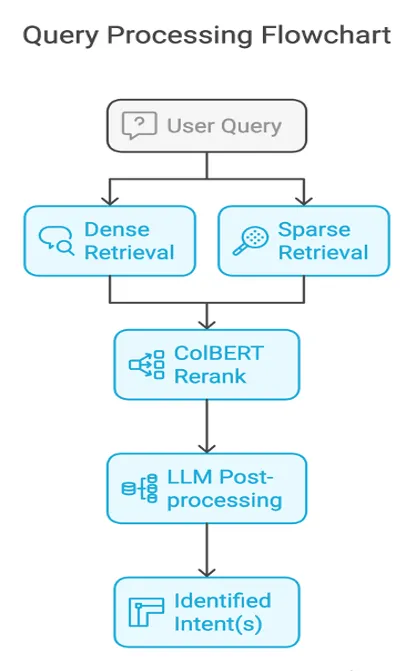
Replacing a BERT plus LLaMA hybrid intent classifier in CVS Health's pharmacy IVR with a multi-vector retrieval pipeline on Qdrant: BM25 sparse retrieval, a fine-tuned dense encoder, ColBERT late-interaction reranking, and an LLM as the final classifier and out-of-scope filter on the top five candidates. Weighted F1 from 0.58 to 0.86 across roughly 1.5M daily customer interactions and 32 distinct pharmacy intents. The public retrospective is on the CVS Health Tech Blog.
Senior Forward Deployed Engineer
Stack
Python · BM25 (sparse retrieval) · Fine-tuned dense embedding model · ColBERT (late-interaction reranking) · Qdrant (multi-vector store) · LLM post-processing (top-5 classification + out-of-scope) · Synthetic data pipeline (~100k labeled queries) · Telephony + streaming ASR/TTS · Observability (transcript review, quality scoring)
Outcomes
- Weighted F1 from 0.58 to 0.86 on a 32-intent pharmacy taxonomy (
rx_refill,store_address,drug_availability,cancel_vaccine_appointment,rx_drug_price, and 27 more). - Largest gains on previously unreliable intents:
drug_availabilityfrom 0.18 to 0.82,available_vaccineandrx_drug_pricereaching 1.0. - Roughly 1.5 million customer interactions per day handled by the new pipeline.
- Three vector representations per item in Qdrant (sparse, dense, late-interaction) with prefetch-plus-rerank wiring to avoid recomputation during ranking.
- 100k synthetic query-to-intent training set generated and a subset used to fine-tune the dense encoder, with cleaner decision boundaries between near-duplicate intents validated on cluster maps.
- Public retrospective published on the CVS Health Tech Blog.
The full public retrospective is on the CVS Health Tech Blog: Transforming Customer Interactions: Evolving IVR Systems for Enhanced Experiences. Everything below is grounded in that article and the work behind it.
What shipped
What shipped is the intent classification layer behind CVS’s pharmacy IVR, which fields roughly 1.5 million calls per day across 32 intents such as prescription refills, store lookups, drug availability, vaccine appointments, and pricing. We replaced a BERT plus LLaMA hybrid with a multi-vector pipeline backed by Qdrant: BM25 sparse retrieval anchors rare drug terms, a fine-tuned dense encoder captures paraphrase, ColBERT late-interaction reranks the merged candidate set, and an LLM does final classification and out-of-scope rejection on the top five. We trained the dense model on a 100k synthetic query-to-intent dataset and used Qdrant’s prefetch plus rerank pattern to keep latency and cost in check. Weighted F1 moved from 0.58 to 0.86, with the largest gains on previously unreliable intents.
What I owned
The migration path from rules-and-grammars IVR to LLM-driven agentic flows, and the retrieval architecture that made it tractable. That meant designing the agent runtime, the tool-use envelope around it, the multi-vector retrieval and reranking stack, and the seams that let the new system coexist with the old one during cut-over instead of demanding a big-bang rewrite. Operationally, this meant preserving the existing transcript review, analytics, and quality scoring surfaces so the operations team kept their playbooks; only the brain changed.
Architecture
Three vector representations per query and per intent example live in Qdrant: a sparse BM25 vector, a dense vector from the fine-tuned encoder, and a late-interaction ColBERT vector. At inference, Qdrant prefetches top candidates from the sparse and dense channels, deduplicates them, and reranks the merged pool with ColBERT. The top five candidates then go to the LLM, which does final classification and out-of-scope rejection. The LLM is the most expensive node, so we earn it: pushing it to the end of the pipeline (rather than using it as a primary classifier) was both cheaper and more accurate on near-duplicate intents like “what’s the price of amoxicillin” versus “do you have amoxicillin.”
Why each retriever earns its place
Dense embeddings alone miss rare or domain-specific tokens; BM25 is the cheapest fix for that, and keeping it in candidate generation costs almost nothing at inference time. BM25 alone cannot handle paraphrase, so the dense channel is non-negotiable. ColBERT was the part I expected least and relied on most: token-level late interaction recovers context like “refill while traveling abroad” that a bi-encoder flattens into a generic refill intent. The LLM only earned its place at the very end, scoring the top five and rejecting out-of-scope queries.
Lessons
The non-obvious lesson from this work is that intent disambiguation in a pharmacy IVR is not a single-model problem; it is a retrieval problem with a classification step bolted on at the end. A fine-tuned dense encoder is necessary but not sufficient, because rare drug names and specific SKUs collapse into nearby clusters and the model loses the lexical signal that actually carries the intent. BM25 is the cheapest fix for that failure mode, and keeping it in the candidate generation stage costs almost nothing at inference time. ColBERT was the part I expected least and relied on most: token-level late interaction recovers context like “refill while traveling abroad” that bi-encoders flatten into a generic refill intent. The LLM only earned its place at the very end, scoring the top five and rejecting out-of-scope queries; using it as a primary classifier was slower, more expensive, and less accurate on near-duplicate intents. The F1 jump from 0.58 to 0.86 came mostly from the worst-performing intents, not the easy ones, which is the metric I now watch first when evaluating retrieval changes in production conversational systems. Compliance, observability, and the operations team are not blockers; they are the leverage that lets you ship LLM-driven flows in a regulated environment.